TL;DR: I trained a convolutional neural network to recognize game genres from screenshots. It worked quite well. Here are some example outputs:

Cities: Skylines
- Predicted genres: Strategy, Simulation
- True genres: Strategy, Simulation
This one is spot on!

Project Cars
- Predicted genres: Sports, Racing
- True genres: Sports, Racing, Simulation
Not bad either. Here the small error lies in predicting not all of the true genres.

Age of Empires II HD Edition
- Predicted genres: Adventure, Strategy
- True genres: Strategy
Also close. Here the model identifies the Strategy genre, but is also predicting one genre too many.

Final Fantasy IV
- Predicted genres: Adventure, Casual, Sexual Content
- True genres: RPG
This one is completely off. To be fair, with the flashy, simple graphics I can kind of understand the Adventure and Casual labels. But sexual content is nowhere to be seen here.
The techniques I used to train the model are fairly standard and will be nothing new to you if you are familiar with neural networks for image recognition(Spoiler alert: I used a standard CNN architecture pretrained on ImageNet). Instead the rest of this blog post is about my experience with applying neural networks to a multi label classification problem, and some of the problems connected to that, in particular
- which loss function should be used?
- how can we measure the performance of the model?
- how do we extract the labels from the output of the network (and why is it nontrivial to do this optimally)?
The source code (Keras/Tensorflow/Python) is available here.
The training data
As training and test data for the network I used screenshots of games on the Steam store. I am not aware of any convenient API to access screenshots for games on steam, so I wrote some web crawling scripts to download screenshots for every game available at Steam, which is more than 12000 games at the time of writing. I used only one screenshot for each game as training/test data, as this allowed me to fit the whole training data in main memory. I did a few experiments with more training data but this did not really lead to performance improvements.
Steam also supplies the genre labels for each game. As one game can have multiple genres (e.g. Action and Adventure), this is a multi label classification problem (one training sample can have multiple classes) and thus more difficult than a normal classification problem.
I slightly modified the genre information. First of all, I removed some genres that had less then 10 games with that label (e.g. Utility and Abenteuer(!?)). I also removed the quite frequent “genre” labels Indie and Early Access, because in my opinion these labels are not genres, as they say next to nothing about the way the games are played.
The remaining 13 genres are Casual, Action, Adventure, RPG, Simulation, Strategy, Sports, Racing, Violent, Gore, Sexual Content, Nudity, and Massively Multiplayer. All in all the genre labelling is far from perfect: popular genres like Shooter, Puzzle or Platformer are absent, and there are two very similar genres for violence and sexual content each. Additionally I doubt that the labeling is very consistent. But the advantage of Steam is the sheer amount of easy to obtain labelled data, and I guess that it is the biggest such dataset available.
Multi label classification with neural networks
For single label classification problems, we would normally use a neural network with one neuron for each class at the final layer, and a softmax activation function. The softmax function makes sure that the output of the network is a probability distribution on the classes, and we can then choose the class with the maximum probability as the prediction of the network.
For example, if we have the three classes Action, Sports and Strategy, our output layer has three neurons. A sample of class Action is encoded by the one-hot vector [1,0,0], which is the target value for training the network on the sample. After training, the output of the network on the sample might be something like [0.8,0.15,0.05], which we can interpret as a prediction of the class Action with a confidence of 0.8.
For multi label classification, we can use the same final layer, but instead of the softmax use the sigmoid function as activation. The sigmoid function has the property that the output for each label will be some value between 0 and 1 - but the outputs do not form a probability distribution on the labels. We can still interpret the output for each label as a probability (or confidence) that the sample has this label, but as the labels are not exclusive, these probabilities can be independent of each other and do not have to sum up to 1. Thus a sample can be assigned multiple labels.
For example, we could now have a sample of labels Action and Sports, which is encoded by the “multi-hot vector” [1,1,0]. This is now the target value for training the network on that sample. After training, the output of the network might for example be [0.8,0.9,0.1], which we can interpret as the model assigning the labels Action and Sports.
Apart from this modification to the final layer, no changes have to be made to the network architecture, so using neural networks for multi label learning is conceptually not very different from ordinary classification tasks. For this problem I used the xception architecture [4] for convolutional neural networks with weights pretrained on ImageNet, and trained a few fully connected layers on top of the convolutional blocks. I also experimented with tuning some of the convolutional layers, but this quickly led to overfitting and reduced performance of the model. Concerning hyperparameters, I got the best results using AdaGrad with a relatively small learning rate (<= 10e-4) and dropout with a low reset probability (about 0.2).
Another thing to consider is the loss function to use, which is the objective we try to minimize in training the model. The standard loss function for classification problems is the categorical crossentropy loss, but this loss requires that there is only one true label for each sample, so it can’t be used for multi label learning. But other standard loss functions like mean squared error or binary crossentropy are fine to use. I achieved the best performance when training using the binary crossentropy loss function, which is also the result obtained by [2].
There is also a loss function called BP-MLL that has been proposed specifically as a loss function for multi label learning [3]. I also implemented that loss function but was unable to achieve any satisfying results with it, as the training always converged quickly to very poor local minima (always predicting the most frequent labels). At least for this specific problem, it seems to be better to follow the advice of [2] and use binary crossentropy together with state of the art techniques such as dropout and ReLU activations to achieve the best possible results.
Performance Measures
For ordinary single label classification tasks it is easy to measure the performance of a model by the classification error rate, i.e. the percentage of incorrectly classified samples. Theoretically we could use the same measure for multi label learning, i.e. a prediction of the model is correct if it contains exactly the true labels of the sample and none other. This is called the zero-one error in this context as we judge each prediction either as completely correct or complety false.
However, this measure is not the most informative we can think of. If we have a screen with true genres Action, Adventure and our model predicts Action, Adventure and Violent, this is a pretty good guess, but if our model predicts Sports and Simulation, that is completely wrong. Using the zero-one error measure we simply consider both of these prediction as equally wrong, while it is more fair to consider different levels of wrongness.
Two important measures in this context are recall and precision. Recall is the fraction of true labels that are correctly identified by the model. In the above example with true genres Action and Adventure, the first prediction [Action, Adventure, Violent] has a recall of 1, as both true labels are identified correctly. The second prediction [Sports, Simulation] has a recall of 0. On the whole dataset the recall can be computed by counting all true labels that are correctly predicted, and dividing that by the total number of true labels.
Recall = count(correctly predicted labels) / count(true labels)
But we can also compute the recall separately for each genre, to find out how our model performs on the individual classes.
Precision, on the other hand, is the fraction of predicted labels that are actually true. In the above example with true labels [Action, Adventure], the first prediction [Action, Adventure, Violent] has a precision of 2/3, as only two of the predicted labels are true labels. The second prediction [Sports, Simulation] has a precision of 0. We can compute the precision on the whole dataset by counting all labels correctly predicted by the model, and dividing by the total number of predicted labels.
Precision = count(correctly predicted labels) / count(predicted labels)
Recall alone is not a good measure of performance: A stupid model that always outputs the label Action will have perfect recall for that genre (but typically low precision). Precision is certainly harder to “cheese”, but a model that by sheer luck identifies one Action game correctly and otherwise never predicts Action will have perfect precision (but most likely low recall). A combination of both these measures is the F1 score, which is the harmonic mean of recall and precision:
F1 = 2 * Recall * Precision / (Recall + Precision)
The F1 score is a performance measure that is widely used for multi label learning, and the one we try to optimize here.
The measures themselves do not say much if we have nothing to compare them to, and if we have no idea how hard the problem actually is. Unfortunately I have not found any previous work on this problem, except this short abstract [1] which does not contain any concrete results. Thus, I chose to compare the performance to that achieved by a human (myself) labeling the test data.
For this purpose I labeled 250 random samples from the test data. In some cases this actually proved quite difficult - I mean, what the hell is this supposed to be?

Or that?


In general, I also found it difficult to judge what the difference between Violent and Gore is - or between Nudity and Sexual Content - and hard to determine whether a game is an online multiplayer game. Since the sample size is quite small (about 10% of the test data) the results have to be taken with a grain of salt, as they are probably quite noisy, especially for less frequently occurring genres.
Learning Optimal Thresholds
There is one more problem to multi label learning: how to we actually deduce the predicted labels from the output? For single label classification, one usually has a softmax activation at the final layer of the network, and can simply take the class with maximum output as the predicted class (as the softmax output can be interpreted as a probability distribution on the classes). But as mentioned above, we can not use the softmax for the multi label case, and use the sigmoid function instead. So for each label the output will be some number between 0 and 1. Note that it is not a good idea to simply take, say, the 3 labels with the highest score, as we do not know in advance how many labels our sample might have.
If our model works reasonably well then on the true labels the output should be close to 1 and on the false labels the output should be close to 0 - in fact this is the criterion we trained it on. Now the naive strategy would simply be to choose the value 0.5 as threshold and treat every output greater than that as true and every output lower than that as false. However, this is not necessarily the optimal threshold that maximizes the F1 score for that label. Maybe our model is a bit too generous in giving out the label Action and still outputs a value of 0.5-0.6 to false positives of this label. Then it would be better to choose 0.6 as the threshold for the Action label. The optimal thresholds can vary from label to label.
Thus we should at least make an effort to find the optimal thresholds. This can also tell us if our model was able to learn a reasonable representation: If the optimal threshold for a label is close to 1 (or 0), then the model probably has not really learned how to identify that genre!
Of course we are not allowed to search for the optimal threshold on the test data, as this would be indirect training on the test data. There is some literature on optimal threshold selection, but I chose here a very simple strategy of choosing for each genre the threshold that maximizes the F1 score for that genre on the training data. As there are only finitely many samples in the training data, there are only finitely many candidate thresholds: the outputs of the model for the training samples in the component of the given genre.
For example, for the Action genre, the optimal threshold is around 0.41, and the F1 score plotted as a function of the threshold looks like this.

This graph does not necessarily have to be unimodal, but if the model learned the class reasonably well that is quite likely.
This is only one of many strategies for extracting labels from the model output. For example, another reasonable approach would be to partition the outputs into “low” and “high” values such that the gap between the low values and the high values is maximal.
Results
The following table compares zero one error, precision, recall, and F1 score on the test data set.
| Measure | Human | Model |
|---|---|---|
| zero-one-error | 0.790 | 0.854 |
| precision | 0.622 | 0.521 |
| recall | 0.519 | 0.523 |
| f1-score | 0.566 | 0.522 |
As we can see, I outperform the model in general when it comes to precision, but I have to work on my recall. But looking just at these global statistics the performance of the model seems to be quite good, which is also the impression from looking at example classifications. Without the threshold selection, the model achieves an F1 score of 0.462.
Now let’s look at the F1 scores for each genre separately:
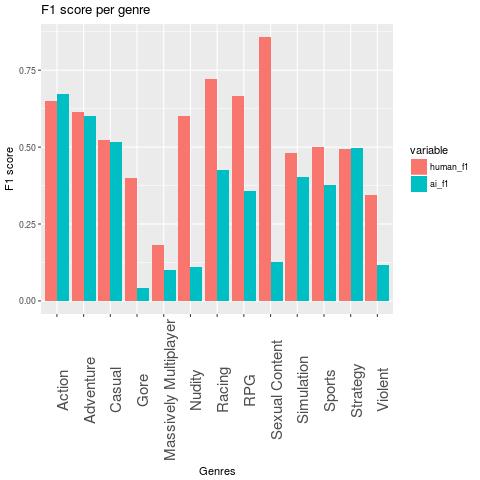
We see that the F1 scores for about half of the genres are comparable to human performance or not much worse. However, on the rest of the genres the performance of the model is really bad, especially for both of the violent and sexual genres and the multiplayer genre. There might be several reasons for that:
- These genres occur less frequently in the training data. Not only are they seen less often in training (which could be fixed by fiddling a bit with the training data), it is also inherently harder to get a good F1 score on these labels. For example, if a label occurs 90 % of the time, then a very stupid model which always predicts this genre achieves an F1 score of about 0.95. For less frequent labels it is harder to achieve good F1-scores. Note that almost never predicting a label leads to low recall and thus also to low F1 scores.
- I think that the labeling for the violent and sexual genres is not very consistent, and they are hard to separate.
- My scores are noisy due to the small test data set. For example, I have perfect recall on the genre Sexual Content, as there was only one example of that genre in my test data sample.
- Even for humans, it is pretty hard to judge from a screenshot whether the game is a multiplayer game. A lot of screenshots just show random scenery or are taken from a singleplayer mode. This also explains my bad performance on this genre.
For the sake of completeness, here are the graphs for precision and recall.
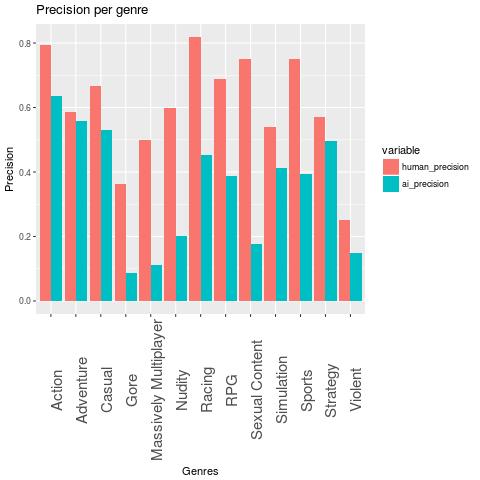
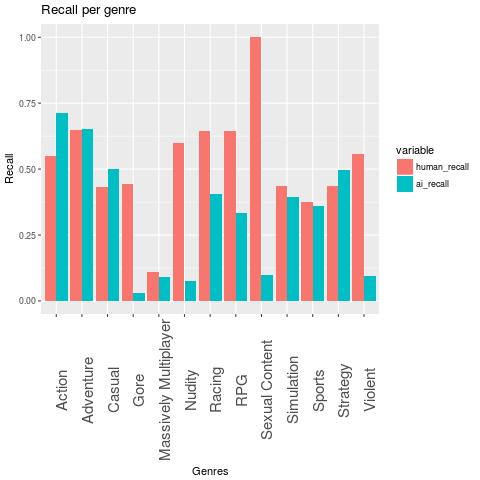
The performance could possibly be improved with more precise genre labellings. One idea would be to use Steam’s user defined tags for this, but I fear that this labelling is also pretty noisy.
Conclusion
To summarize, neural networks are also a great tool for multi label classification. My suggestions are:
- Use the binary crossentropy loss and state of the art techniques like Dropout, ReLUs, Adagrad
- Use adequate performance measures like the F1 score
- Improve the performance of your model by optimal threshold selection
References
[1] Predicting video game properties with deep convolutional neural networks using screenshots
[2] Nam, Jinseok, et al. “Large-scale multi-label text classification—revisiting neural networks.” Joint european conference on machine learning and knowledge discovery in databases. Springer, Berlin, Heidelberg, 2014.
[3] Zhang, Min-Ling, and Zhi-Hua Zhou. “Multilabel neural networks with applications to functional genomics and text categorization.” IEEE transactions on Knowledge and Data Engineering 18.10 (2006): 1338-1351.
[4] Chollet, François. “Xception: Deep Learning with Depthwise Separable Convolutions.” arXiv preprint arXiv:1610.02357 (2016).